Wikidata5m
Info
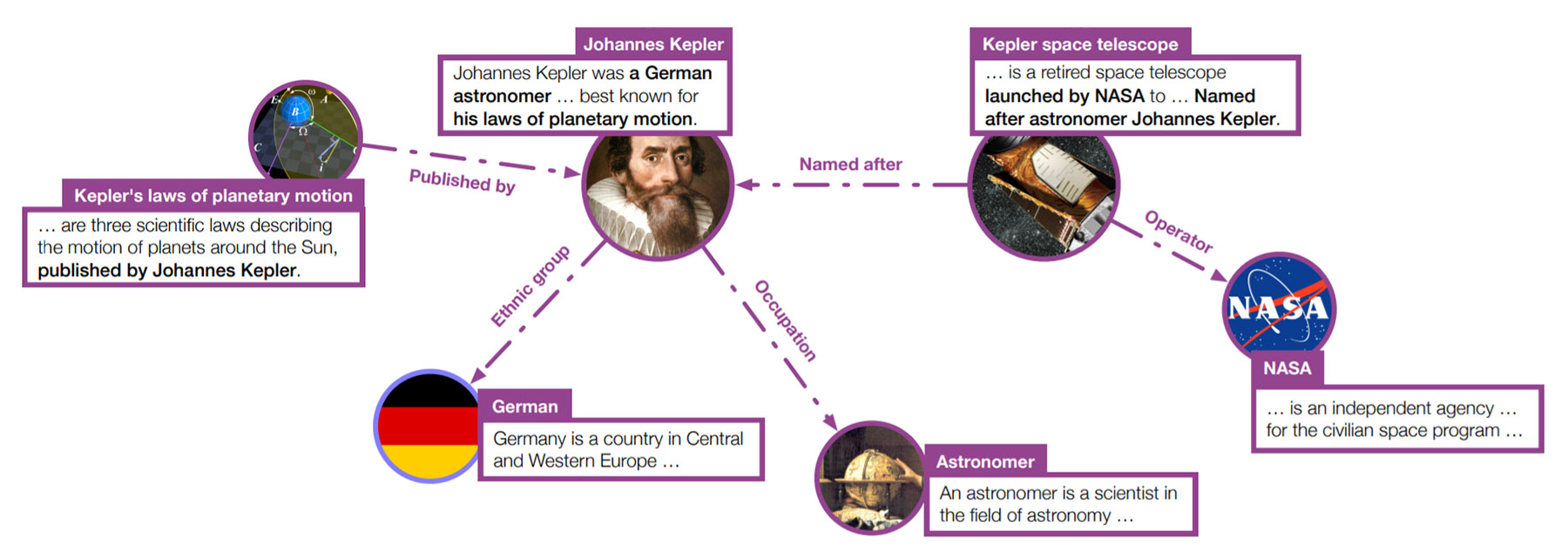
Wikidata5m is a million-scale knowledge graph dataset with aligned corpus. This dataset integrates the Wikidata knowledge graph and Wikipedia pages. Each entity in Wikidata5m is described by a corresponding Wikipedia page, which enables the evaluation of link prediction over unseen entities.
The dataset is distributed as a knowledge graph, a corpus, and aliases. We provide both transductive and inductive data splits used in the original paper.
| Setting | #Entity | #Relation | #Triplet | |
|---|---|---|---|---|
| Transductive | Train | 4,594,485 | 822 | 20,614,279 |
| Valid | 4,594,485 | 822 | 5,163 | |
| Test | 4,594,485 | 822 | 5,133 | |
| Inductive | Train | 4,579,609 | 822 | 20,496,514 |
| Valid | 7,374 | 199 | 6,699 | |
| Test | 7,475 | 201 | 6,894 |
Data
- Knowledge graph: Transductive split, 160 MB. Inductive split, 160 MB. Raw, 168 MB.
- Corpus, 991 MB.
- Entity & relation aliases, 188 MB.
For raw knowledge graph, it may also contain entities that do not have corresponding Wikipedia pages.
Format
Wikidata5m follows the identifier system used in Wikidata. Each entity and relation is identified by a unique ID. Entities are prefixed by Q, while relations are prefixed by P.
Knowledge Graph
The knowledge graph is stored in the triplet list format. For example, the following line corresponds to <Donald Trump, position held, President of the United States>.
Q22686 P39 Q11696
Corpus
Each line in the corpus is a document, indexed by entity ID. The following line shows the description for Donald Trump.
Q22686 Donald John Trump (born June 14, 1946) is the 45th and current president of the United States ...
Alias
Each line lists the alias for an entity or relation. The following line shows the aliases of Donald Trump.
Q22686 donnie trump 45th president of the united states Donald John Trump ...